What If AI Agents Had CI/CD?
Building a workflow that evaluates, snapshots, and deploys agent instructions across multiple AI tools.

Technology evolves at a pace that feels almost impossible to keep up with. Every week a new model appears. Every month a new coding assistant promises to be faster, smarter, or more capable than the last. Cursor, Gemini CLI, Claude Code, Copilot, Windsurf etc , the ecosystem keeps growing, and honestly, that is indeed exciting.
But while experimenting with these tools, one thought had always had me wondering. Software engineering has mature CI/CD pipelines. Before code reaches production, it is tested, validated, reviewed, and deployed through a controlled process. Entire teams trust these systems every day because they reduce uncertainty and create confidence in what gets shipped.
Why doesn't the same idea exist for AI agents?
What happens when an agent modifies instructions, updates rules, introduces a risky dependency, or accidentally exposes sensitive information? Most of the time, we trust the output and move on. The pace of development is so fast that convenience often wins over verification. I wanted to explore a different approach. That curiosity eventually became BinaryByte.
The Idea
I started wondering what a CI/CD-inspired workflow for AI agents would actually look like , which definitely was not another model, coding assistant or framework.
Instead, something that sits between change and deployment.
Something that evaluates modifications before they are propagated across tools. Something that records the state responsible for those decisions. Something that creates a deployment gate rather than blindly pushing updates forward.
That simple idea became the foundation of BinaryByte.
From Repository to Package
One of the most satisfying parts of this project wasn’t writing the code itself but packaging it.
For the first time, I wasn’t just building a tool that lived on my machine. I was building something that could be installed and used by anyone with a single command.
pip install binarybyte
A few moments later, the CLI is available.
binarybyte --help
No lengthy setup guide.
No dependency treasure hunt.
No cloning required for someone who simply wants to try it.
Also, There is something surprisingly satisfactorily about seeing a project move from a local folder to a package that can be installed anywhere. It feels less like a collection of scripts and more like a real piece of software.
The Workflow
At its core, BinaryByte follows a very simple philosophy.
A change should be evaluated before it is distributed.
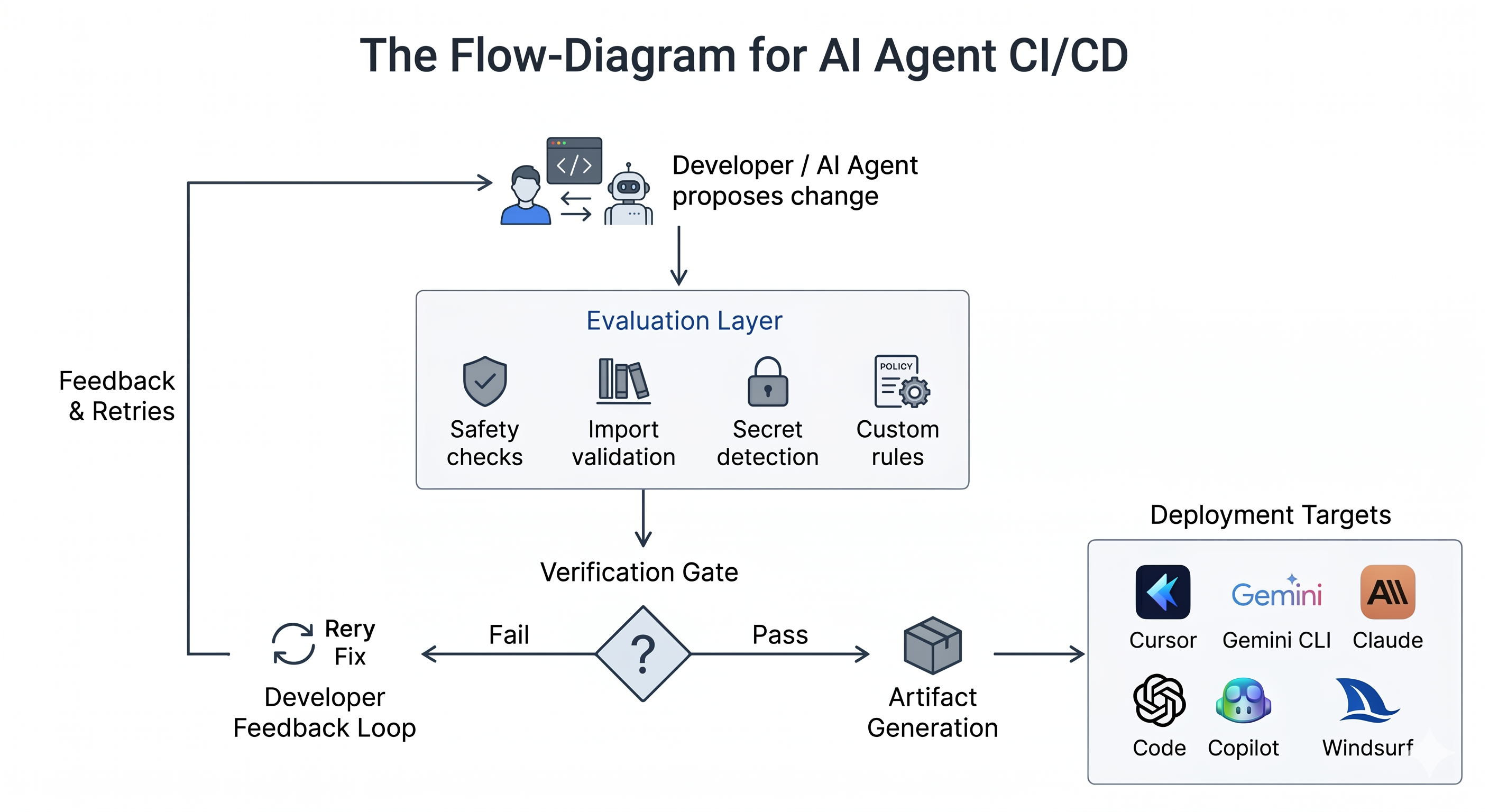
Every change enters the evaluation stage first. /image A verdict is Every change enters the evaluation stage first and a verdict is generated, as well as a snapshot of the associated state is stored and only after passing evaluation can deployment proceed.
The goal isn’t to replace human judgment, it never really was!
The goal is to introduce guardrails before changes spread across multiple agent ecosystems.
A Walk Through BinaryByte
The journey begins with initialization.
binarybyte init
This creates the workspace BinaryByte uses to maintain configuration, state, evaluation results, snapshots, and deployment history.
As work progresses, state can be maintained and shared.
binarybyte state add --key coding_style --value "prefer explicit imports"
The idea behind state management came from a simple observation: context matters(a lot actually).
Agents often behave differently depending on instructions, memory, and conventions accumulated over time. Rather than treating every execution as an isolated event, BinaryByte keeps track of state and its evolution.
When a change is proposed, it can be evaluated.
binarybyte eval run --git-range HEAD~1..HEAD
During evaluation, BinaryByte can perform safety checks, inspect imports, detect suspicious patterns, validate configurations, and execute additional custom checks provided by the user.
The result is not just a pass-or-fail decision.
A verdict is created alongside a snapshot of the state that existed at that moment. That means decisions become traceable rather than ephemeral.
If I ever want to inspect how state evolved, compare snapshots, or understand why a particular decision was made, that information remains available rather than disappearing after execution.
And if the verdict passes, deployment becomes available.
binarybyte deploy run
The deployment stage translates verified information into formats understood by different AI tools, allowing a single evaluated source to be distributed consistently.
What I personally liked about this workflow was that deployment became a consequence of trust rather than a default action. Passing evaluation is not just a green checkmark but the requirement for propagation.
Designing for Evolution, Not Permanence
One realization kept surfacing while building BinaryByte.
The challenge wasn’t supporting today’s tools(its often easier to have things in a certain deterministic environment) instead, the goal was surviving tomorrow’s tools. When a project starts, it is tempting to hardcode assumptions. Support a handful of integrations, connect everything directly, and move on. It works well in the beginning because the ecosystem feels small and predictable but
the AI ecosystem is neither.
A few months ago, some of the tools I regularly used barely existed. A few months from now, entirely new workflows will probably emerge. Building around specific names would have meant rebuilding parts of the project every time the ecosystem shifted.
That pushed BinaryByte toward a more adapter-oriented design.
Instead of treating deployment targets as core functionality, they became extensions. The evaluation engine remains the same. State management remains the same. Deployment targets become interchangeable components that can evolve independently.
In a way, the architecture mirrors the problem it tries to solve.
The rules may change, The agents may change and The deployment targets may change.
But the process of evaluating changes before distributing them remains constant. That idea influenced more than just the plugin architecture. It also influenced how I thought about state itself. If change is inevitable, then moving forward shouldn’t be the only operation a system understands.
Sometimes the newest version isn’t the best version.
Sometimes an experiment fails.
Sometimes a change that looked correct during development turns out to be the wrong direction.
That’s why BinaryByte stores versioned snapshots and allows movement across previously evaluated states. I wanted the system to treat history as a first-class citizen rather than a log that nobody ever revisits. In many ways, the ability to fall back is just as important as the ability to move forward. A workflow that embraces change should also respect recovery.
Looking back, that separation between evaluation, state management, and deployment turned out to be one of the most valuable design decisions in the project and probably my favorite one. Each layer has a single responsibility, and because of that, they can evolve independently without forcing the entire system to change alongside them.
Interestingly, publishing the package was probably the easiest part of the journey. The harder challenge was deciding what should remain stable and what should be allowed to change. Looking back, most of the engineering effort was not spent writing commands — it was spent drawing boundaries between evaluation, state management, and deployment so that each could evolve without breaking the others.
Looking Ahead
Personally, I feel we are standing at a rather interesting point in technological history.
Growing up, the world of Doraemon felt like pure fantasy. Intelligent assistants, conversations with machines, tools that could understand intent rather than instructions and those ideas belonged in cartoons and science fiction.
Today, they feel surprisingly achievable.
Every few weeks, a new model appears. Every few months, a new framework promises to change how we build software. The pace is exciting, but it also makes me wonder what parts of this ecosystem are actually permanent.
Will today’s coding agents still exist five years from now?
Maybe or Maybe not.
What I do believe is that some ideas survive regardless of the tools built around them. Distributed systems didn’t disappear when new programming languages appeared. Version control didn’t disappear when new IDEs emerged. CI/CD didn’t disappear when deployment platforms evolved.
The implementations changed. The principles remained.
While building BinaryByte, I found myself thinking less about supporting a particular agent and more about preserving a process. Models may change. Agent frameworks may change. Even the deployment targets supported by BinaryByte today will probably look different in the future.
What I wanted to explore was a much simpler question:
If we trust evaluation before deployment in software engineering, shouldn't we be asking similar questions for AI agents?
BinaryByte became my attempt to explore that idea and interesting enough It also became my first published Python package.
Whether the project grows into something larger or simply remains an interesting experiment, I am glad I built it. It taught me how to think about tooling, architecture, distribution, and perhaps most importantly, how to build for change rather than against it.
Because if technology has taught me anything so far, it is that the tools rarely stay the same however
the fundamentals usually do.
Learn More
For installation instructions, architecture details, supported targets, and the complete command reference, check out the README.md in the repository. Needless to say, you can check out my other works as well.
